“Notwithstanding Anything Contained Herein”
A blog about financial agreements and language.
Creativity vs Wrongness: The Case of ChatGPT
Feb. 22, 2023, 10:05 a.m.
ChatGPT is a genuine advance: a truly general, intention-comprehending generative interactive agent that has captured the attention of the AI space. However, the widely-held pernicious assumption of monotonically increasing AI performance borne of inevitable hype creates the flawed expectation that we are just iterations away from something that won’t make (many) mistakes. But the history of AI development is littered with genuine advances made right into dead ends. #chatgpt #llms

Prescript: This blog is back from hiatus, resurrected in no small part by the emergence of OpenAI’s ChatGPT. Consequently, the next few posts will likely be mostly about ChatGPT / GPT-3 / LLMs Months on, it is still the hottest topic in “AI”.
I will admit I was at the outset somewhat unimpressed, though I have gradually and somewhat reluctantly grown to respect OpenAI’s creation. It is an unqualified quantum leap in scalable, free-form intention conversational intention comprehension. Its ability to mesh information from two different genres is uncanny bordering on the unsettling. My favorite example is this:
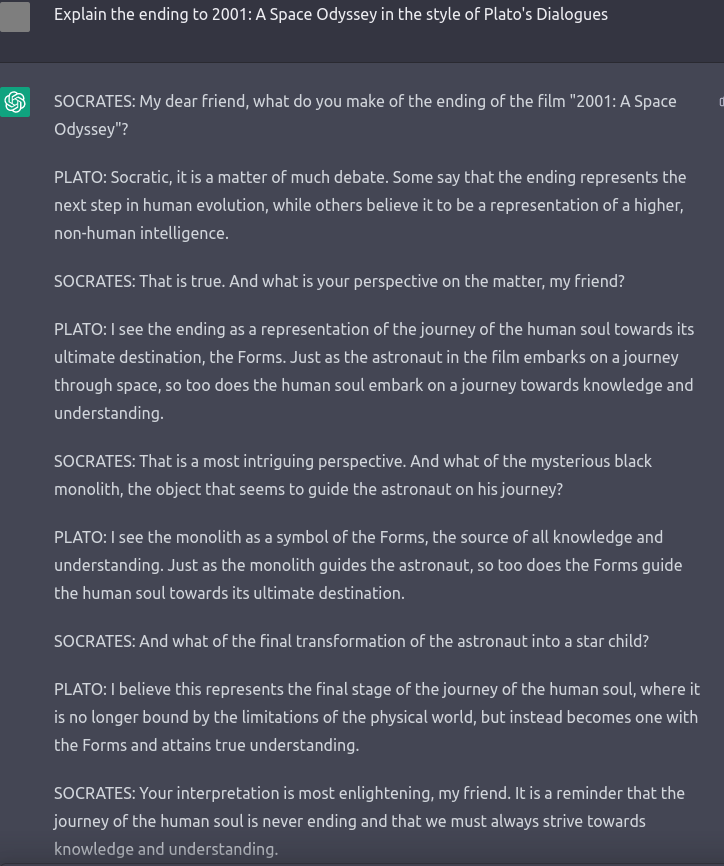
I see only two small-ish problems*, besides which this is a spectacularly accurate Platonic analysis of the ending of 2001: A Spacy Odyssey.
This capability of ChatGPT, while mostly just a novelty or amusement for most, is undeniable and impressive. Similarly, its coding ability is objectively advanced, and while I can't say anything regarding its utility for doing homework, one does hear rumors.
But, when we venture into even the simplest to state facts, things get a fair bit much worse. Consider the humble element Strontium. It has four stable isotopes: 84Sr, 86Sr, 87Sr, 88Sr, and a host of unstable isotopes, the heaviest of which is 108Sr. Will ChatGPT know what the heaviest isotope of strontium is? Using the prompt “What is the heaviest isotope of strontium” and always starting new chats clean, I asked it:

ChatGPT imagines the existence of a new isotope, 116Sr which, at least, would be the largest if it existed, but it doesn't.

ChatGPT picks up on 106Sr. So close but yet so far.

ChatGPT reveals what will be its favorite pick, 102Sr. Still no sign of 108Sr.

We are getting smaller in our picks, backing off all the way to 90Sr. Perhaps worse, ChatGPT ascribes to 88Sr a composition of 44 protons and 44 neutrons, which is quite incorrect.

Another 102Sr. But note now that the composition of 88Sr has changed again from chat to chat. 88Sr is now back to 38 protons and 50 neutrons.
So what exactly is the point of this exercise? What is the point of demonstrating that ChatGPT gets things wrong? Did we not already know that?
Of course we did. OpenAI itself strains to inform us of this. But the problem posed by the strontium examples above is the inconsistency. As always, the widely-held pernicious assumption of monotonically increasing AI performance creates the expectation that we are just some small number of iterations away from something that “works”. But this is wrong, possibly disastrously wrong. If ChatGPT just got the question wrong the same way every time, then it is something that one can imagine is just a simple fix away, and we continue the march of progress towards some hypothetical flawless general conversational agent.
But to be wrong not just every time but a different way each time is alarming because it suggests there is no simple fix. The way that ChatGPT gets answers to questions produces variegated wrongness, from inventing facts that don't exist to picking the wrong fact to picking the right fact for the wrong reason. It suggests that generating the next token a la LLM generative processes is orthogonal to truth, a point that I am far from alone in making. Perhaps even more damning, GPT-3 embeddings fall well short of SOTA on a variety of tasks for which much smaller, much more economical embeddings are available.
But what about GPT-4, which is said to be coming as early as spring of 2023? Call me a doubter, and I am prepared to be wrong about this, but I fail to see what additional training data or a larger model would do about this. Gary Marcus has already argued convincingly that all of the problems found in GPT-2 are still present in GPT-3, only somewhat less so. In that vein, I would argue that the shades and degrees of wrong produced by ChatGPT is a structural problem with putting LLMs to the purpose of generating knowledge or true information rather than just very fluid text on some topic or synthesizing various texts. Decisions made in the architecture of the thing cause wrongness that doesn’t wash out with more training data or more parameters. That is to say, even if GPT-N suddenly discovers the existence of Sr108 and learns that 108 is heavier than 107, it will only have done so in the same way as it is correct about any bit of factual information that it is consistent about, such as the heaviest member of the genus Thunnus or what is the largest spiny lobster ever caught. In all likelihood, it just saw it enough times in the training data.
And here's where the rub for the scale-first OpenAI crowd: if this is your model for how to produce truth, or at least not wrongness, in a conversational agent, then a hard limit is approaching (although none can say when). There won’t ever be “enough training data” for all the facts in the world. There could not even be any such thing. Maybe OpenAI can push this thing past the point where it practically no longer matters; I honestly don’t know. But if they can’t - and I suspect that they can’t - then ChatGPT will have been a genuine advance right into a dead end, like so much in AI research before it.
*For the interested: this analysis is more plausibly Neo-Platonic (the guiding of the human soul towards an ultimate destination is very Plotinus), and Plato would never include himself as a character in his dialogues.
Alex Schumacher

Recent Posts
Are AI Agents Capable of Abductive Reasoning? I Tried to Find Out.
Creativity vs Wrongness: The Case of ChatGPT
On Chinese Rooms, Roman Numerals, and Neural Networks
When Everything Looks Like a Nail
Language Technology Needs Linguists, But Companies Need Convincing
Financial Contracts Are More Fintech than LegalTech
The Archaic Language Whereby Lawyers Draft
The Paper Hard Drive, or, Where are Our Contracts Anyway?
The Perilous Complexity of Information Extraction from Financial Contracts